MIT Biology Class - Reading Between the Lines (4)
 Lecture Note:
Lecture Note:
Geneticists have been surprised to discover that some genes actually overlap each other, meaning that the same stretch of DNA can be involved in the code for more than one protein. This is very common in prokaryotes, which have less DNA in which to pack their genetic instructions, but it has also been discovered to occur in eukaryotes, which have a more roomy genome.
My thoughts:
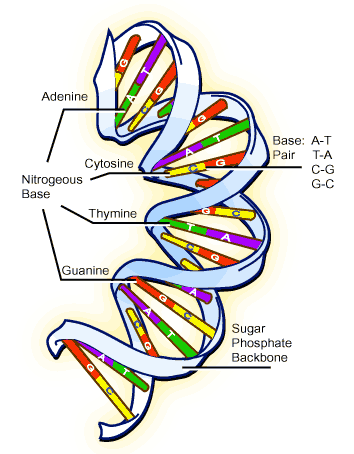
The amino acid arrangement, which makes up the protein polypeptide chain, is coded for by the nucleic acid molecules (nucleotides) in DNA. These nucleotides come in 4 flavors, which are represented by the letters A T G and C. A series of 3 nucleotides (a codon) codes for each individual amino acid. So, for example, TAC codes for tyrosine, while GAA codes for glutamate. It should be noted that there are 64 possible combinations of these sets of 3 nucleotides, while there are only 20 amino acids, so, many of them can be represented by more than one codon, e.g., both TAT and TAC code for tyrosine. Additionally, some combinations represent "start" and "stop" codons1, which bookend the gene and define a "reading frame" — the gene is contained within the reading frame.
A large molecule known as RNA polymerase reads the DNA and assists the messenger RNA in acquiring a copy of the gene, which will be elsewhere translated into a protein. It reads the DNA in these codon groups, but it is not as though it begins at the start of the DNA molecule and reads along it in groups of 3 nucleotides; it can attach at any point and only begins its transcription work when it encounters an ATG triplet (the start codon). So, in theory, there could be one at the start of the DNA strand, one starting from the 2nd nucleotide in the strand, one starting at the 3rd nucleotide in the strand, etc.
For example, a stretch of DNA might look something like this:
...ATGCATGTCATACCATAGCTAGAG...
The ATG at the beginning would start the gene sequence and it would end once it had reached a stop codon, which in this case is the TAG sequence. So the resulting reading frame and 4 amino acid gene2 would look like this:
...ATG CAT GTC ATA CCA TAG CTA GAG...
(Start, Histidine, Valine, Isoleucine, Proline, Stop)
But not so fast: if you look at the original sequence you will notice that ATG can be found a bit further in, and there is another TAG later down the line as well. So if we adjust our starting offset just a tad we can find a whole different gene in this same stretch of DNA, like so:
...A TGC ATG TCA TAC CAT AGC TAG AG...
(Start, Serine, Tyrosine, Histidine, Serine, Stop)
Can you see why this would be a stunner for geneticists to find? This is like discovering that your recipe for chicken pot pie also contained the recipe for laundry detergent if you drop every second letter, or that your favorite song is also the national anthem when played backwards. It is hard enough to explain how new genes can come into existence by random mutations; now we must explain how something so delicately intertwined as this could come about.
It is a problem whether it is claimed to come about gradually or all in one step. If you say that the overlapping genes came into existence together, then you have only increased the statistical improbabilities on already problematic equations. If you say that this happened gradually (first one gene appeared and then tweaks occurred to bring the second into play), then you have added profound constraints upon the process that is proposed to bring genes into existence. It is one thing to say that a functional gene could by chance and degree be constructed upon a stretch of unused DNA, but to say that it can arrive upon the back of a functioning gene without upsetting its vocation stretches credulity on principle alone. I may just as well say that my wife can slowly change her pot pie recipe into a crypto-detergent recipe without making my son vomit at any point that she follows it and served him the product.
~~~~~~~~~~~~
End Notes:
1. The start codon ATG actually codes for the amino acid methionine. The three stop codons, TAA, TAG, and TGA, do not encode an actual amino acid.
2. As you may remember from an earlier lecture note, the average protein consists of at least 150 amino acids.
posted by Paul @ 12:54 PM
22 comments
![]()
![]()

{kind=link}